无侵入服务流量复制实践
黄杰 / 2023-01-17
本文介绍查询服务迁移场景中,通过全流量复制,来检测新服务正确性和可用性。内容包括tcpcopy原理、无侵入部署、监控曲线与统计,以及过程中提高效率措施。相比功能测试、压力测试,能够更真实全面的检测新服务。
1. 背景
查询服务迁移上云(Koala)。
当前线上部署 4 个网关集群,每个网关集群监听2个端口的,分别是 {消息长度}+JSON 和 JSON+0x00 的二进制协议,网关再根据请求中的 cred_id 字段,路由到具体的服务,共有服务100+,网关和服务之前采用 gRPC 协议。客户端通过 8 个 L5 发现这 4 个网关集群的服务并进行访问。
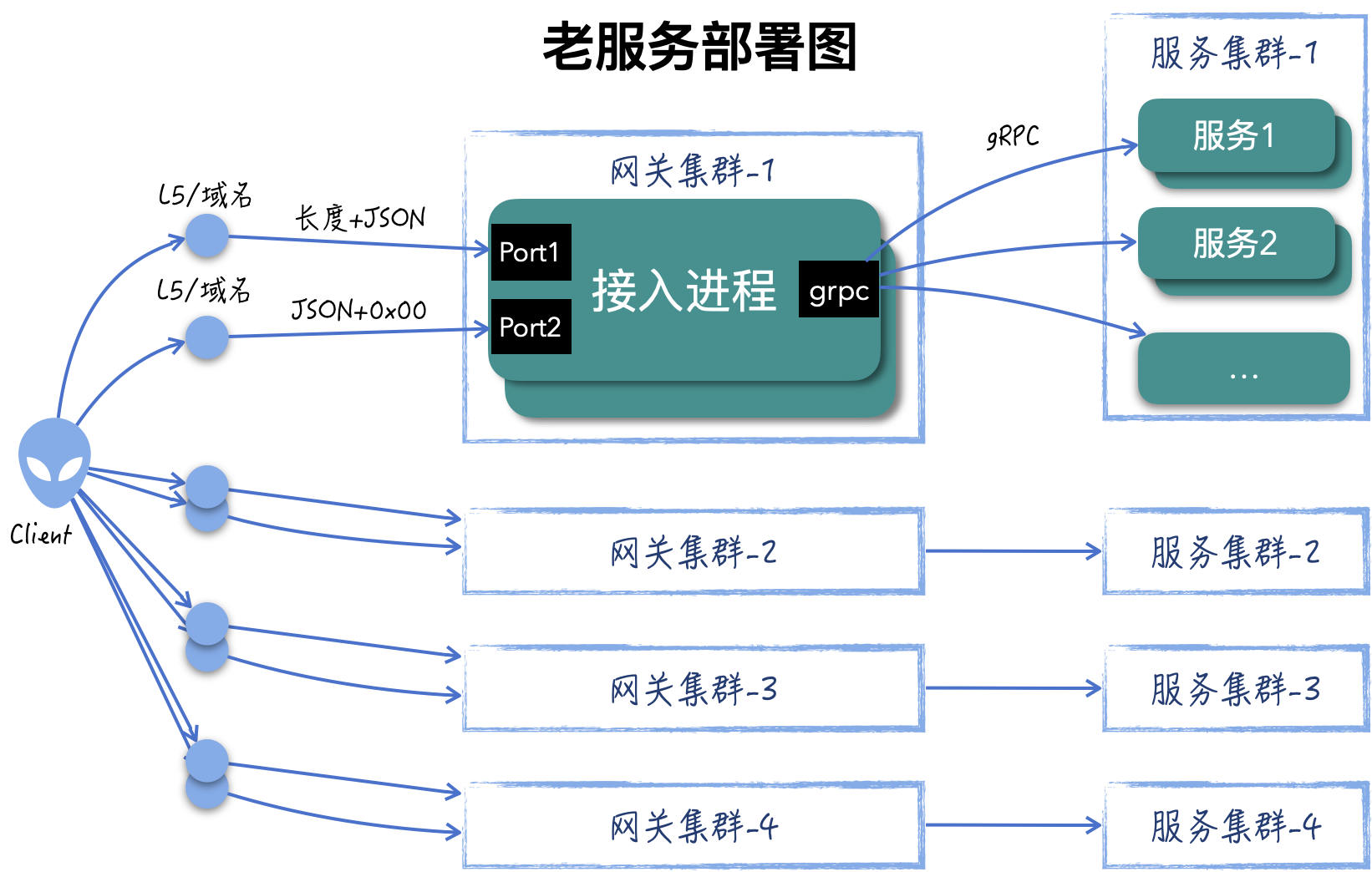
Koala 南天门网关能够转发 HTTP 请求。在迁移到 Koala 之前,各个服务已经做了改造,改成接收 HTTP/JSON 协议,框架内部会将 HTTP/JSON 转成 PB 消息,使用之前的逻辑。网关也进行了改造,以接收原来两种二进制协议,转发后端协议由之前的 gRPC 改成 HTTP。
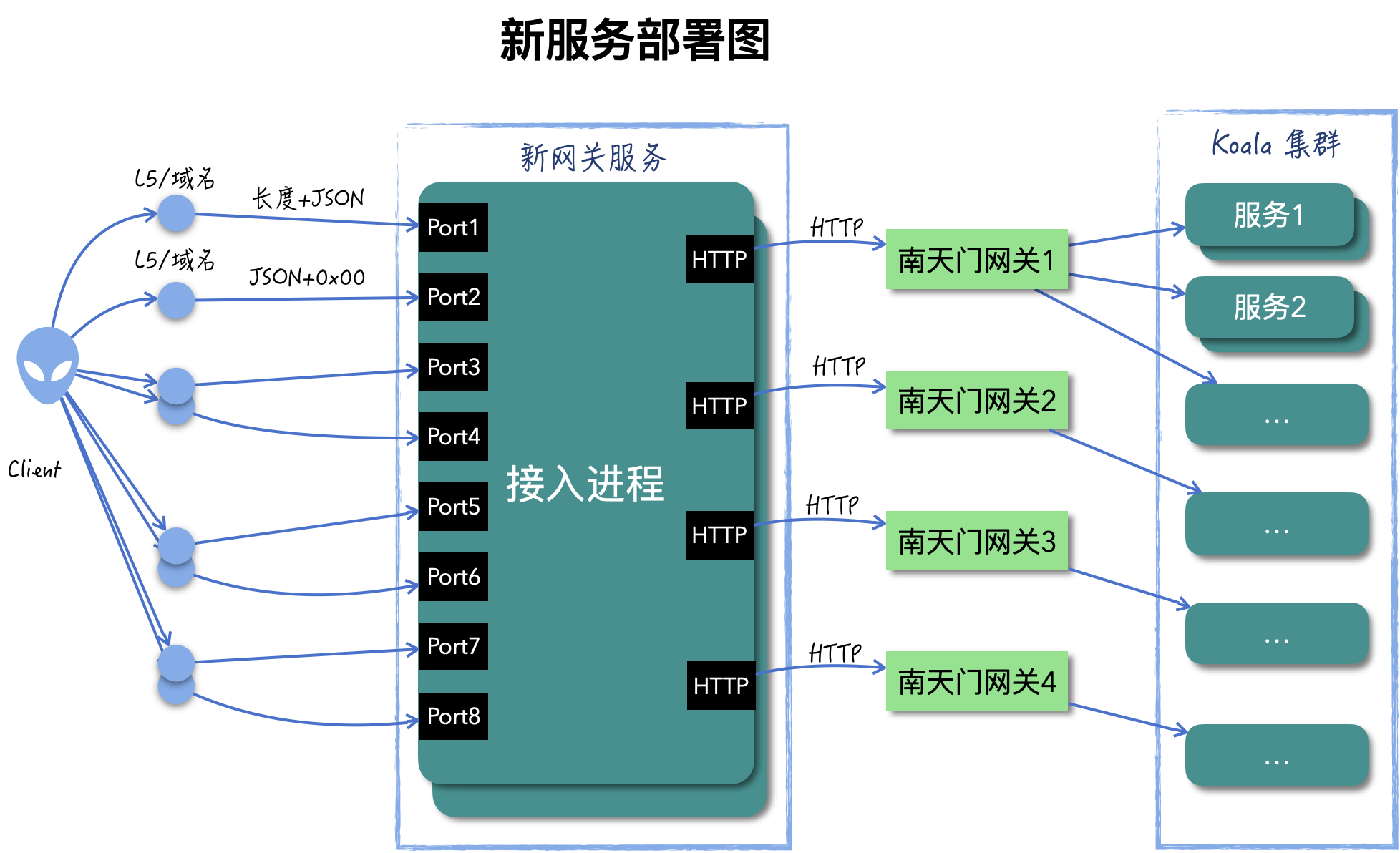
当服务迁移完成,可以通过更新 L5 的方式逐渐将流量导入到新集群。
由于服务的前端分布很广泛,直接进行流量导入,很难及时感知错误;部分服务的请求量很低,再加之 L5 权重控制,短时间内难发现问题,上线切换时间会被拖的很长。
又因为均为查询服务,可以复制线上流量到新的网关,排查哪些服务有异常,在真正服务线上请求之前都解决掉。
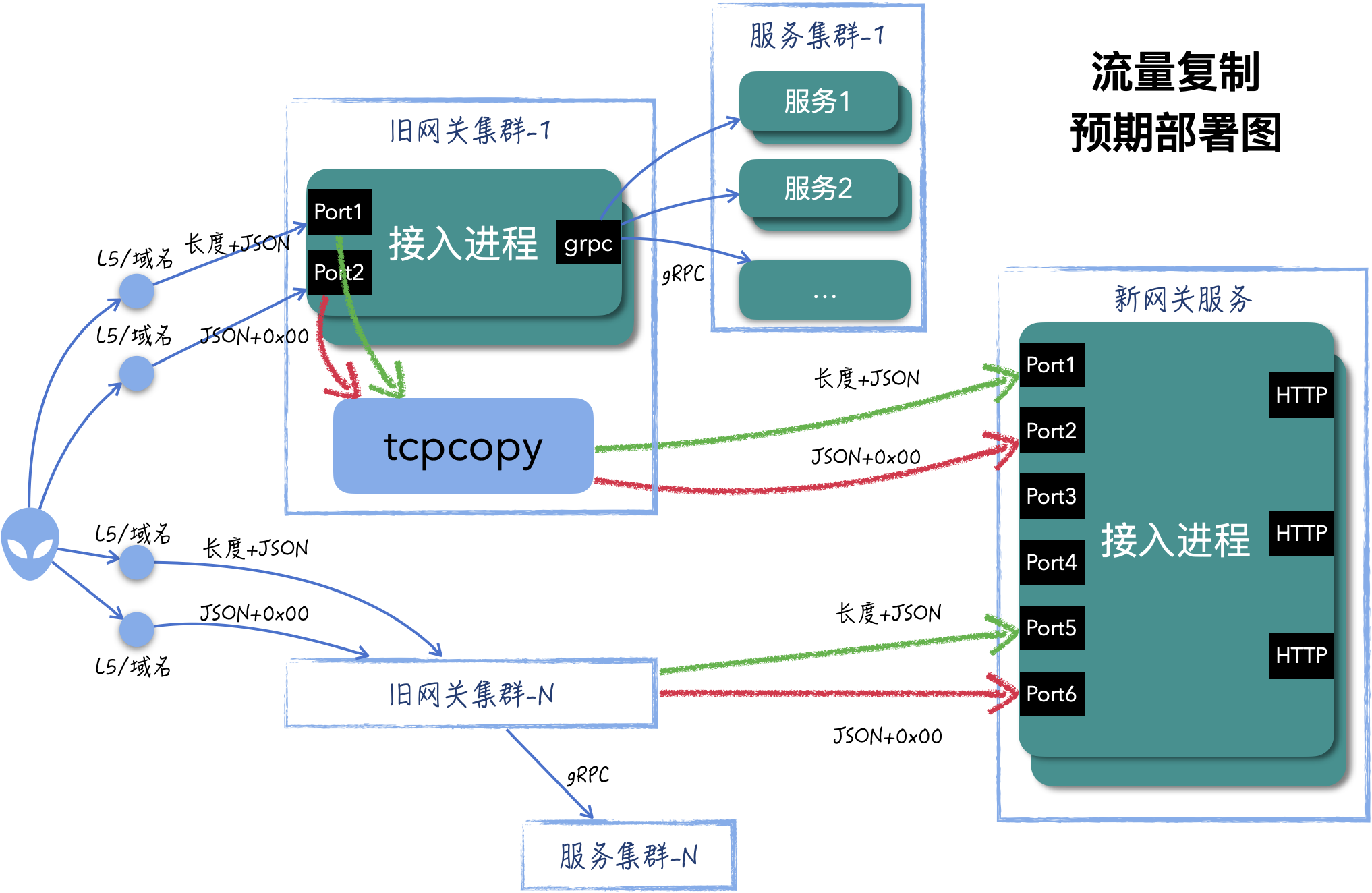
2. 流量复制
2.1 tcpcopy 工具简介
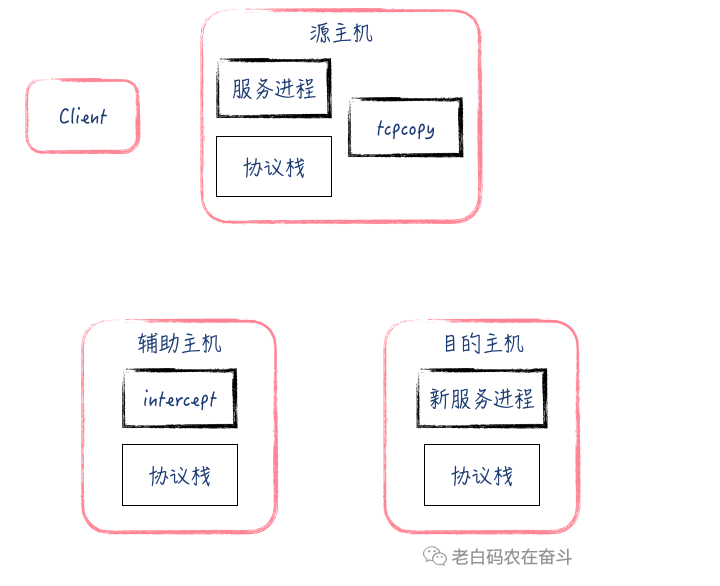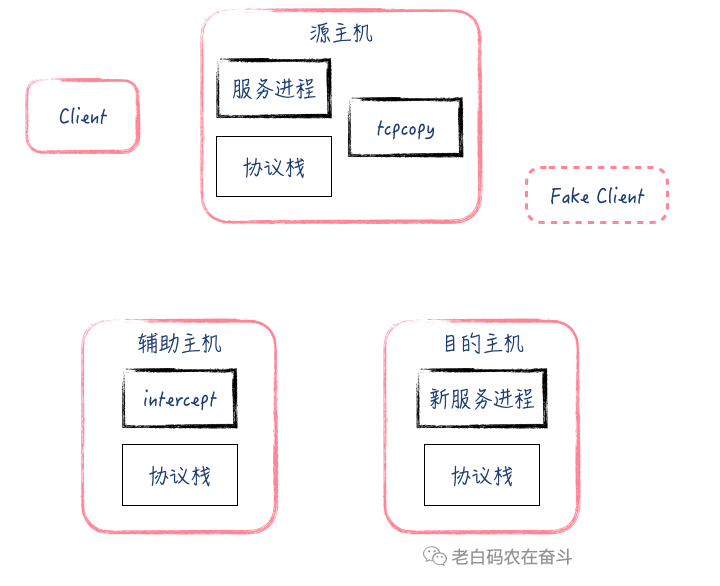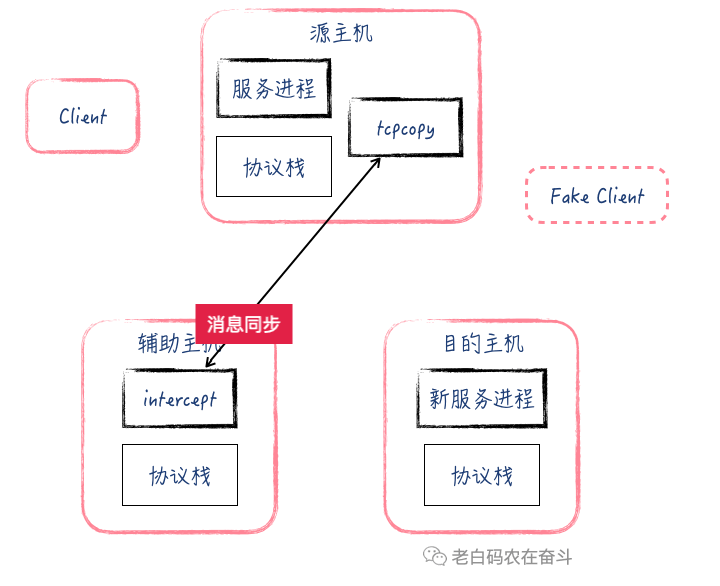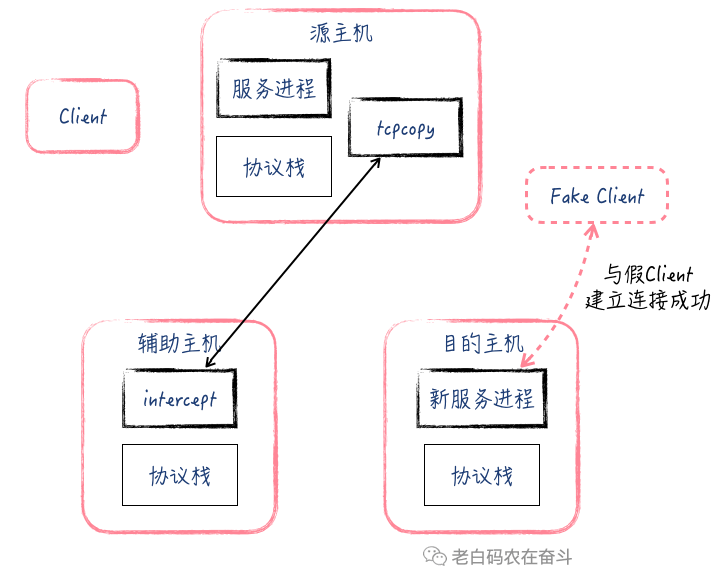
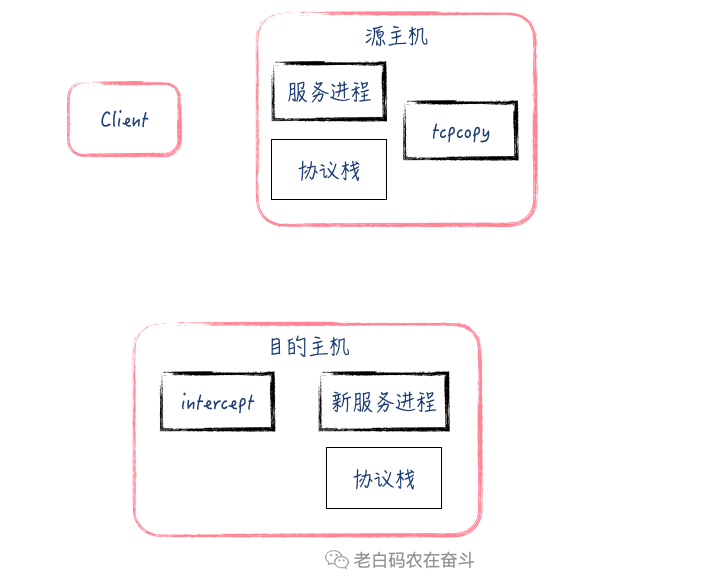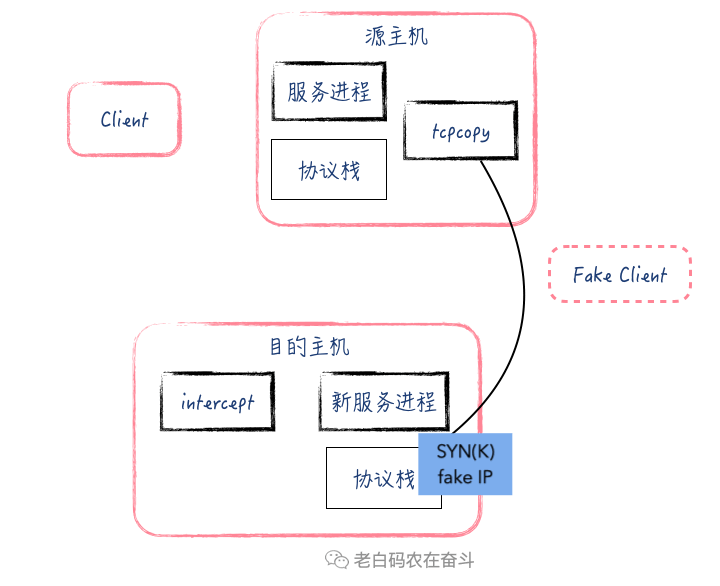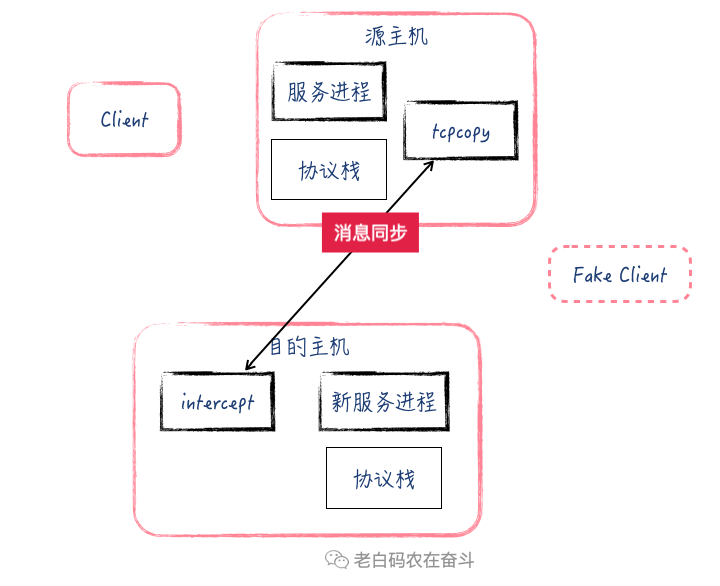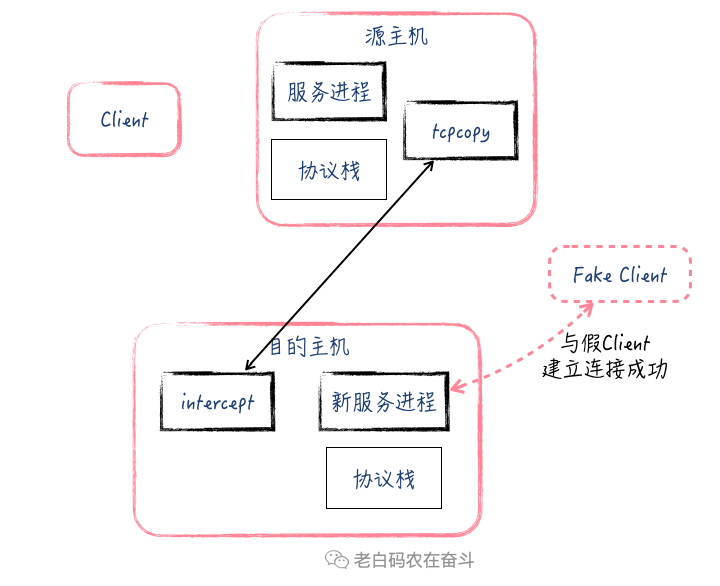
tcpcopy 工具涉及三个角色:源 Server、目的 Server、辅助 Serve,两个可执行文件:tcpcopy、intercept。
其原理比较简单:
- 源 Server 上,tcpcopy 监听线上输入流量,使用 raw socket 方式将 TCP 包中的目的地址修改为目的 Server 的地址,将源地址修改为虚假Client 地址,发给目的 Server
- 目的 Server 需要配置路由规则,将发给虚假 Client 地址的包指定路由到辅助 Server
- 辅助 Server 部署 intercept,捕获目的 Server TCP回包,并将信息通报给 tcpcopy
- tcpcopy 收到 intercept 通报的收包信息之后,继续将后续的 TCP 包发给目的 Server 的包
这里以建立连接的三次握手为例,再将上述原理用动画演示并做详细解释:
- 源 Server上,tcpcopy 通过 libpcap 等库针对服务端口收包(
dst port)进行抓包,然后将 IP 包复制一份,将源地址修改成虚假地址+将目的地址改成目的Server的地址。 - 源 Server 上的 tcpcopy 进程还通过长连接与辅助 Server建立连接,同步一些连接的消息。
- 目的 Server 收到建立 TCP 连接的请求,会正常去处理,然后将 ACK 包路由到辅助 Server
- 辅助 Server 上的 intercept 进程指定端口抓包,收到目的 Server发送的与虚假地址建立连接的 ACK 包,intercept 抓取到这个 ACK 包之后,将 TCP 头中的信息,通过跟 tcpcopy 进程建立的通道发送到源 Server
- 源Server 上的 tcpcopy 根据收到 TCP 头信息,再次发给目的Server 一个ACK,此时目的主机与假的 Client 连接建立完成
通过在源 Server、目的 Server 和辅助 Server 上抓包,也可以清楚地看到这中间的交互过程。
源 Server 上进行抓包,目的地址是源 Server IP 且端口是 31000 的包,会被复制发往目的 Server 的10030端口(中间 30.255.203.2 为虚假IP):

目的 Server 上抓包,可以看到虚假地址与其建立连接的过程:

使用步骤
根据官方文档,使用 tcpycopy,有三个步骤(2和3顺序不能变,不然 tcpcopy 拉不起来):
- 目标 Server上增加路由,将指定的 IP 路由到辅助 Server
- 辅助 Server 上启动 intercept,会拉起端口,用于接受 tcpcopy 的连接
- 源 Server 上启动 tcpcopy,指定监听-转发规则,与 intercept 建立连接
具体参数说明
tcpcopy 的具体启动方式如下。其中,80 是源机器上的要监听流量的端口,61.135.233.160:8080 是要转发的地址和端口,-s 61.135.233.161 和 -p 28003 分别表示 intercept 的地址和端口,-c 62.135.200.x 表示的是虚假 Clien IP 地址,要改成9.xxx开头的,不然路由不过去。后边的网络路由问题会有详细的说明。
./tcpcopy -x 80-61.135.233.160:8080 -s 61.135.233.161 -p 28001 -c 62.135.200.x
一个 tcpcopy 进程可以同时监听多个端口,对应转到多个端口 (80->8080, 81->8081):
./tcpcopy -x 80-61.135.233.160:8080 -x 81-61.135.233.160:8081 -s 61.135.233.161 -c 62.135.200.x
一个 intercept 只服务一个 tcpcopy 进程。intercept 因为具体的启动指令,类似于 tcpdump,-i any 表示捕获所有网卡(包括 lo),-F 'tcp and (port 10010 or port 10011)' 表示监听 TCP 端口 10010 和 10011 的两个端口, -p 28001 表示要监听的端口,以供 tcpcopy 建立连接。-d 表示 daemon 模式,-l 用于指定日志文件。
./intercept -i any -F 'tcp and (port 10010 or port 10011)' -p 28001 -d -l t1.log
2.2 网络路由问题
tcpcopy 官方文档上介绍的在目的 Server 使用 route 指令,将发往虚假IP的转发到辅助 Server 的方案,在简单网络环境下是适用的,但是稍微复杂一点的网络环境便会遇到问题。
本小节在会介绍可能遇到的问题,同时也会补充一些相关的网络知识点。
假源地址的选择
tcpcopy 文档中,介绍拉起 tcpcopy 的示例如下:
./tcpcopy -x 80-61.135.233.160:8080 -s 61.135.233.161 -c 62.135.200.x
这个 -c 62.135.200.x 表示复制流量的假的源 IP 网段,我们在实际用的时候,一定要进行修改。原因是我们内网并没有这个网段,当这个以这个网段为源地址的 IP 包在内网进行转发的时候,要么会在中间路由的过程中被 Drop,要么会被 iptables 给 Drop,是无法被目的 Server 收到的。
我这里都改成了新网段的 30.255.xxx.xxx 的源地址。
route 设置网络不可达
在目的 Server 上使用 route 指令设置,选择辅助Server IP 地址作为 Gateway 地址,返回“网络不可达”的失败:
# route add -net 30.255.203.0 netmask 255.255.255.0 gw 10.10.224.174
SIOCADDRT: 网络不可达
以下是目的Server的地址信息:

原因是目的 Server 和 辅助Server并不在一个子网上,无法直接将 IP包直接转给辅助Server:目的Server 字网网段 9.85.162.0/23,辅助 Server IP 10.10.224.174 明显是不在同一个网段的。
route 设置仍无法转发
即使是两个 IP 在同一网段,通过 route 指令添加路由规则成功,也可能无法达到转发到辅助Server的目的。
使用两个同一网段的两个 IP 进行测试(最后点分数字是 197 和 174):
- ① - 在197上将设置将
30.255.203.0/24网段的 IP 包路由到 174 - ② - 在174上抓取源 IP 为 197 的包
- ③ - 在197 上通过 telnet 发送 TCP 包到 174,在174上可以看到抓包
- ④ - 在197 上通过 telnet 发送 TCP 包到
30.255.203.1,在 174 上无法抓到包
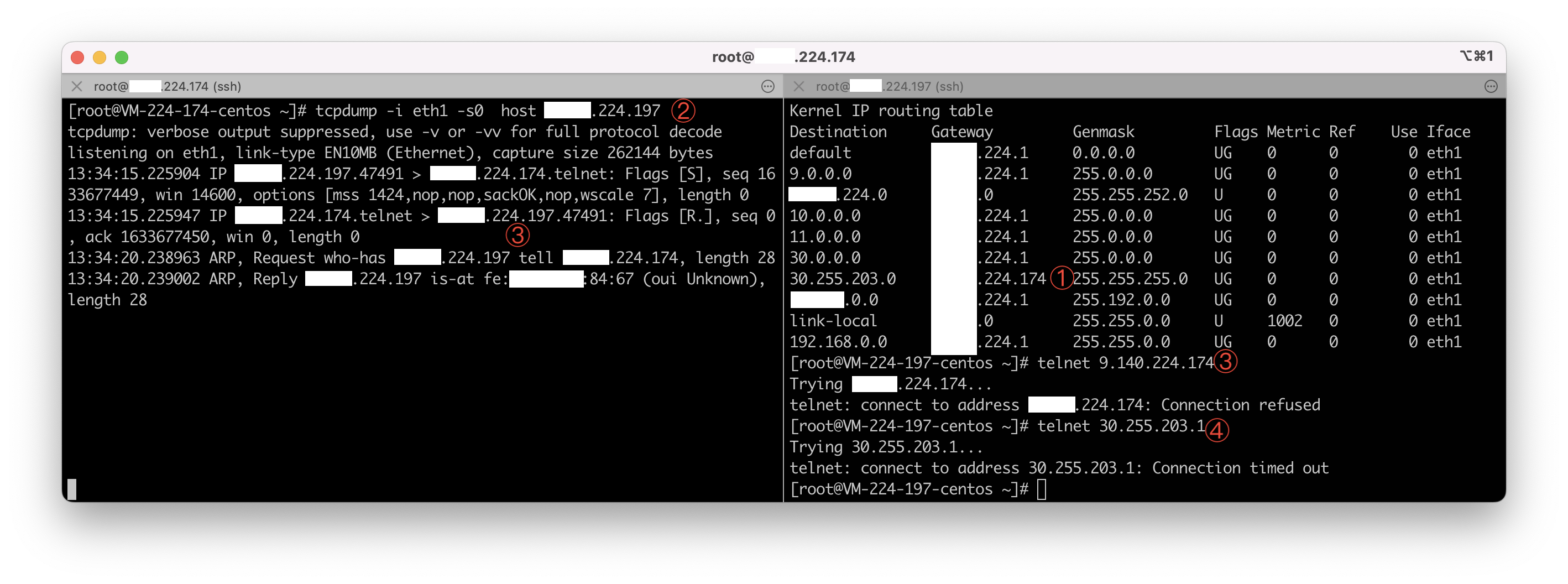
因为两个节点的连接,不是直接连通的,而是通过中间的交换机/路由器。要将源地址是30开头的 IP 包从 197 发到 174,经过中间路由节点时,路由器会根据自己的路由表进行转发。
这里有一个 ARP 代理的概念的:路由器连接两个机器,在197 想获取 174 以太网地址时,被告知了一个假的(路由器的)以太网地址,这样的话,即使是同一局域网下 197 和 174 的通信也不是直接通信的,而是通过路由器进行的:

2.3 简化方案
鉴于以上介绍可能发生的问题,可以使用简单方案减少上述问题的发生:将 intercept 进程启动在目标Server上,则目标Server不需要增加路由,其本身就能处理发往虚假地址的 IP 包。这样的部署方案,省掉了辅助 Server 的角色。
Q:为什么 intercept 可以部署在独立机器,也可以部署在目的主机上,而且启动指令还一样?
A:因为 interept 是监听源 IP 为目的主机的地址或源端口为目的主机的端口的 TCP 包,在目的主机或辅助主机上这两种包都是相同的
这样的部署方式缺点也非常明显,在目标 Server 上启动 intercept 比只添加一条路有规则更具有侵入性:1. 需要有目的主机的操控权限,2. intercep的部署影响目标 Server 服务性能的评估,3. 事后需要单独的部署和清理。下一小节会介绍实际测试中使用的无侵入的部署方案。
2.4 无侵入方案
新网关提供的 IP 是一个 CLB 地址,无法直接在上边部署 intercept,这里实现上采用无侵入的代理方式进行流量复制转发。进而带来了很多好处:
- 对新服务性能无影响
- 无需关心服务容器是否会重启,事后也无需额外清理服务,难以维护
- 单节点上更容易抓包、分析、统计、监控
实际部署
最初部署,使用一台独立机器,在上边部署着:
- intercept 用于和 tcpcopy 之间进行通信(多个intercept分别对应多个机器的tcpcopy)
- Nginx 代理,作为TCP中间代理,接收 tcpcopy 复制过来的流量,转发给下游的网关
- tcpdump 进程监听网络,打印到标准输出,协议是 JSON文本,大小在一个TCP包内,可以直接进行解析和统计
- 通过管道接收 tcpdump 的标准输出,进行简单的 JSON 解析,使用 Prometheus Client 暴露指标
- 启动 Prometheus 容器,通过 volumn 将对应的数据持久化到本地磁盘
- 在 Koala 上部署 Grafana,配置 Prometheus 数据源
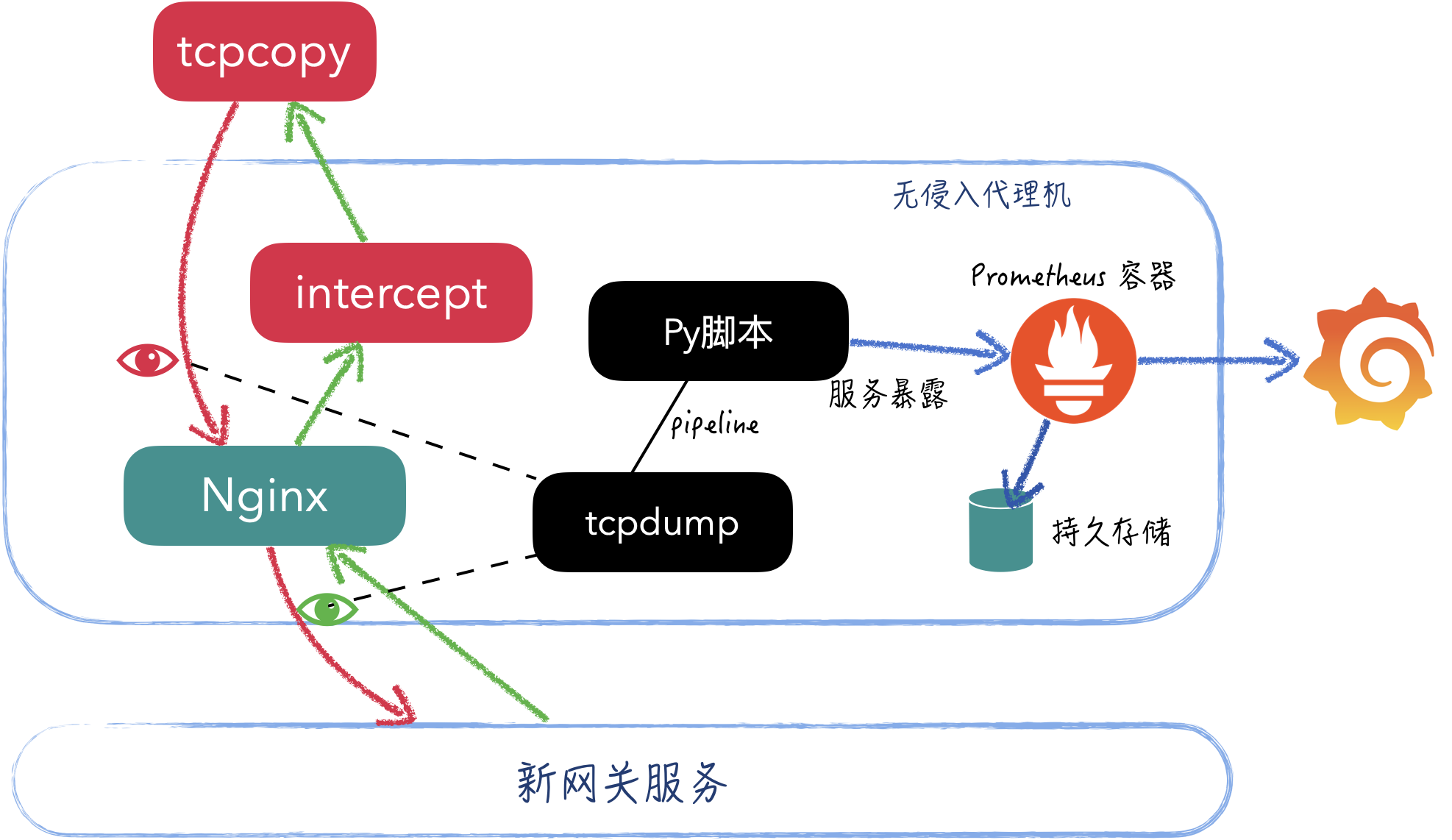
另外,这里从两个流向进行监控,后边监控部分会对此进行解释。
Nginx 代理
Nginx 可以实现 TCP/UDP 的反向代理,但是需要在构建 Nginx 的时候,带上 --with-stream 选项。详细可参考 《Nginx Doc - TCP and UDP Load Balancing》
构建过程:
tar zxf nginx-1.22.1.tar.gz
cd nginx-1.22.1
./configure --prefix=/data/nginx --user=www --group=www --with-http_ssl_module --with-http_flv_module --with-http_stub_status_module --with-http_gzip_static_module --with-pcre --with-stream
配置示例:
stream {
server {
listen 12345;
proxy_pass stream_backend;
}
upstream backend_18600 {
server 10.10.10.12:18600 max_fails=3 fail_timeout=30s;
}
}
Prometheus 容器
利用 Docker 能够轻松地运行任何进程,不用安装、方便清理。
直接使用 Docker 运行 Prometheus,只需要将 Prometheus 的数据文件,通过 volumn 的方式挂载就可以,即使 Docker 容器重启,数据也会持续保存:
mkdir traffic_copy_prom && cd traffic_copy_prom
mkdir prometheus && chmod 777 prometheus
docker run -d -v /sys/fs/cgroup:/sys/fs/cgroup:ro --network="host" \
-p 19090:9090 -v $PWD/prometheus:/prometheus \
-v $PWD/prometheus.yml:/etc/prometheus/prometheus.yml \
prom/prometheus \
--storage.tsdb.retention.time=1y \
--config.file=/etc/prometheus/prometheus.yml
!!! 这里有一点需要注意的, Prometheus 默认存储是 15 天过期,如果要加长存储过期时间,可以使用 --storage.tsdb.retention.time=1y 选项。本来本文详实的监控图片,但阳了一个星期回来一看流量复制初期的图表曲线都没了,:"-(
启动 Prometheus 容器之前,需要在工作目录下创建 prometheus.yml,添加上之前拉起的 Python 脚本对应的暴露服务地址即可:
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['10.10.224.174:13001']
- job_name: 'ingress_stat'
static_configs:
- targets: ['10.10.224.174:13011']
Grafana 服务
因为我们所处的办公环境,无法直接通过 IP 访问 IDC 的服务,必须要配置对应域名以进行访问。而通过 Koala 或 GDP 等服务开发平台可以快速地创建一个 Grafana 服务并配置对应域名。
docker pull grafana/grafana-enterprise
# 以上获取的镜像 commit 为 c05a39f58366
docker push c05a39f58366 mirrors.tencent.com/jasonzxpan/grafana
在 Koala 上新创建服务,选择这个镜像即可:
待容器拉起之后,配置后端服务(3000端口),创建南天门网关,即可进行访问。
2.5 全流量复制
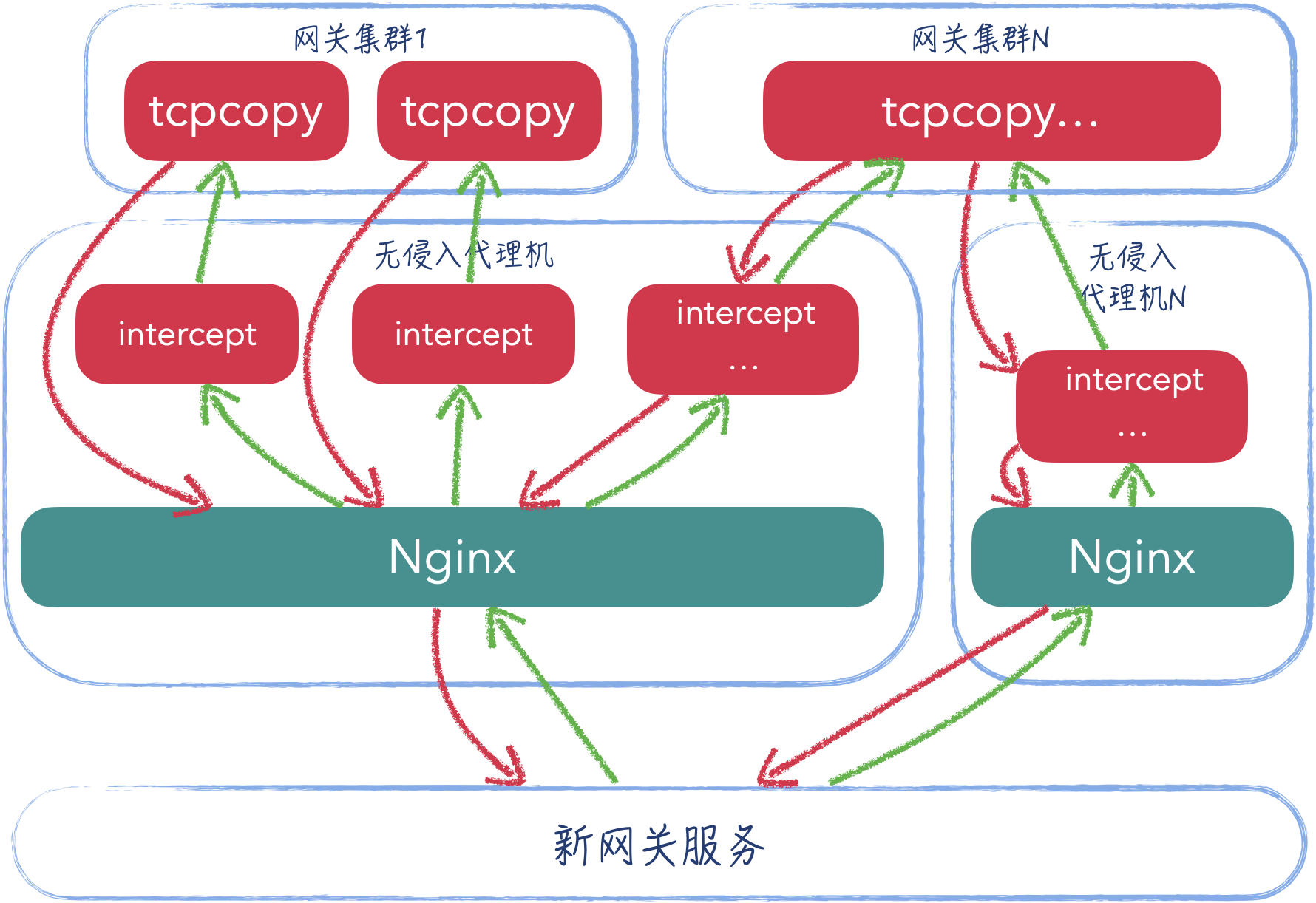
流量复制能检测出服务的逻辑是否正常,而全流量的复制则能够检查新服务的负载是否能够满足要求。
没有使用 tcpcopy 自带的流量放大功能。而是在每台旧网关启动一个 tcpcopy,在无侵入代理机上启动一个 intercept 服务该 tcpcopy,而且这里部署了 3 台无侵入代理机。这样部署是基于以下几个考虑:
- 单台老网关上如果放大流量,会影响现网的服务能力。一旦流量增加,该网关会有严重的放大,有高负载的风险。
- 单台无侵入代理机,无法承载 4 个网关集群的所有流量,无侵入代理机无状态,可以并行多启动几台
3. 监控统计
3.1 监控指标
开始流量复制之后,需要对复制流量的请求和结果进行统计,以确定新的服务是否都能正常服务。正常服务的标准包括:服务是可以访问的、错误率与原服务相同、访问高峰能够支撑与原来相同的请求量。
根据这些评判标准,这里的监控分为两部分:
- 代理接收前端的请求,用于判断流量拷贝是否符合预期
- 代理发往后端的返回,用于判断后端服务是否正常
前期单网关网关流量视图
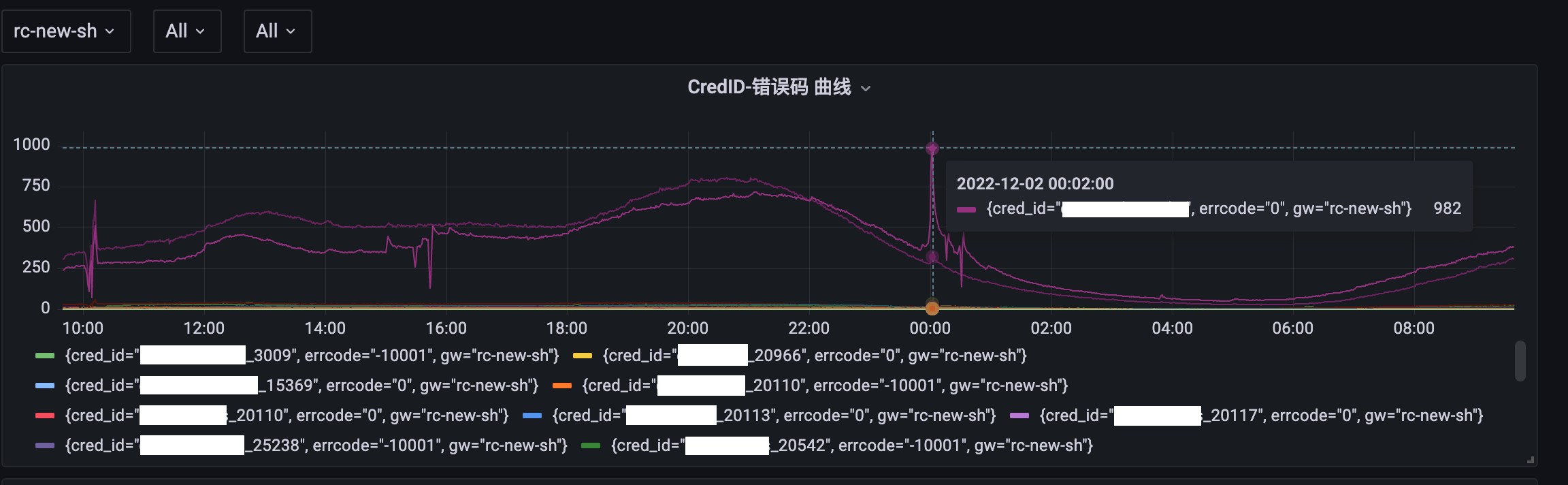
全流量复制单网关流量视图
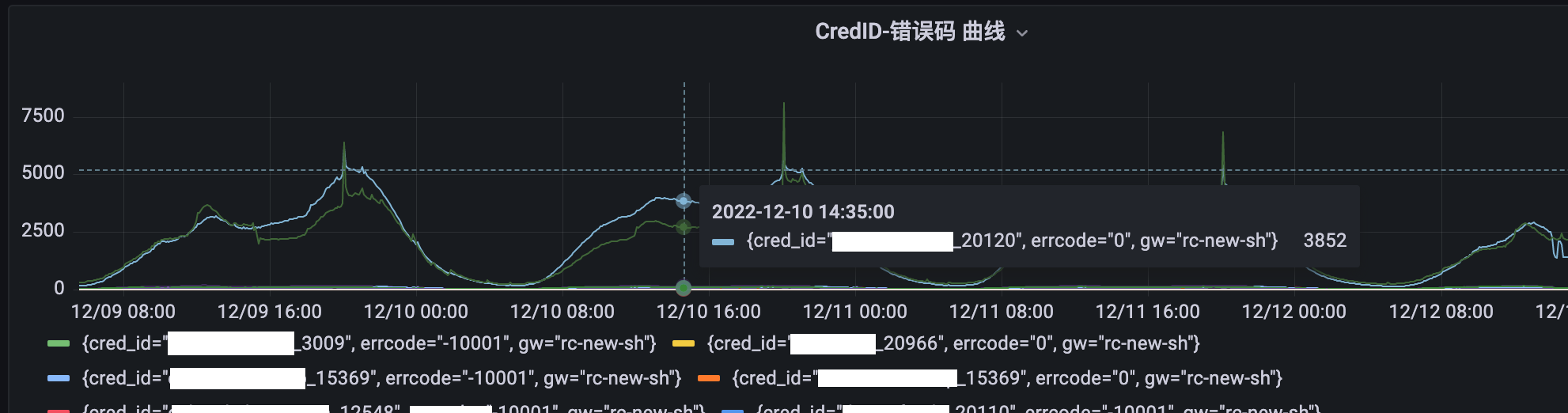
某新服务在高峰时部分失败
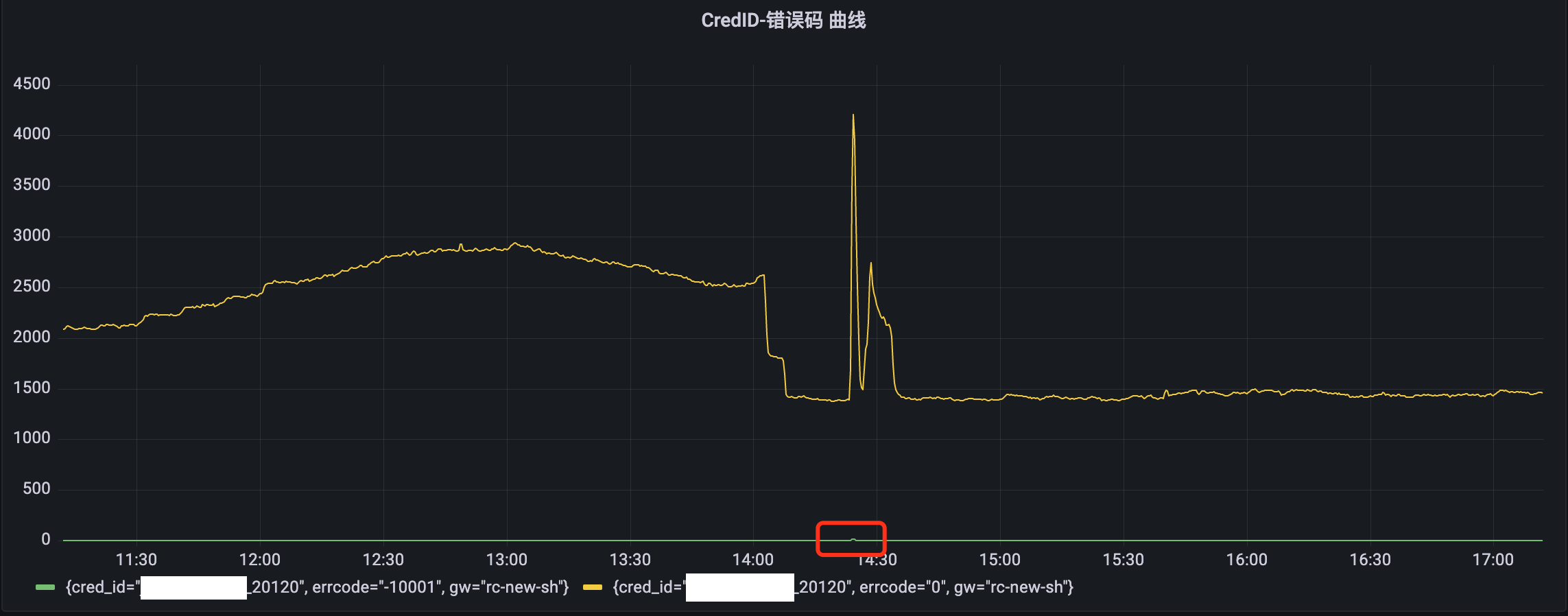
L5调整之后部分服务仍有访问
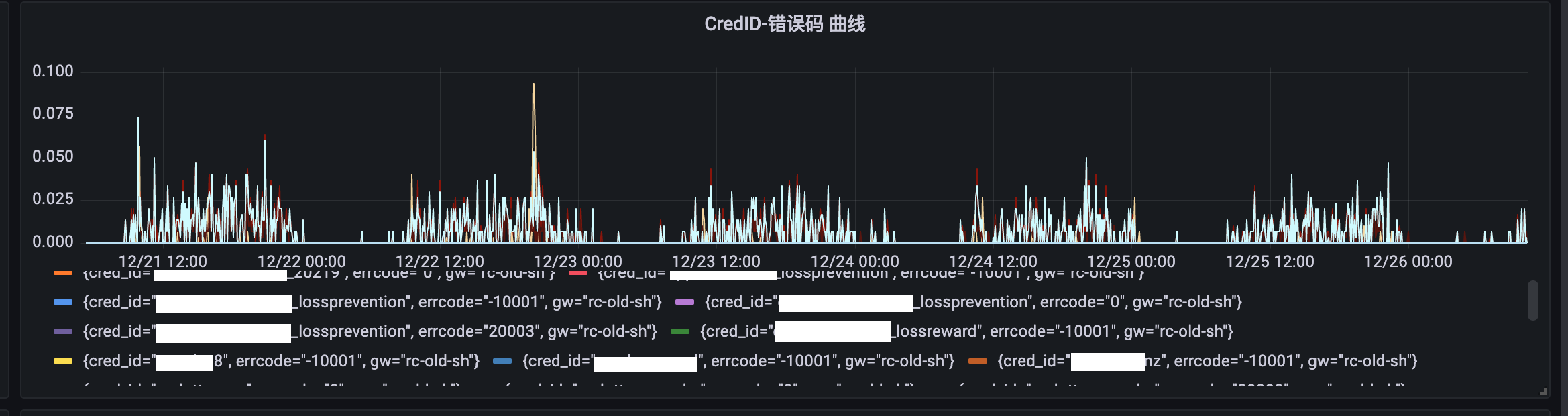
3.2 网络抓包与统计
因为请求中都带有服务ID,绝大多数返回中会带有服务ID和错误码。因此,无需进行连接级别的监控统计,而是可以直接通过抓取 TCP 包的方式,得到活动的请求和返回信息。
而具体的实现上,是通过 tcpdump 抓取内容 + Python 统计暴露的方式进行:
# 监控发往上游的请求,统计入口信息
tcpdump -i eth1 tcp "dst port 48100 or dst port 48011" -s0 -A | \
python3 expose_metrics_ingress.py rc-new-test 13011 &
# 监控上游返回信息,统计错误码
tcpdump -i eth1 tcp "src port 48100 or src port 48011" -s0 -A | \
python3 expose_metrics_errcode.py rc-new-test 13001 &
指标暴露脚本比较简短,贴在这里供参考:
from prometheus_client import Counter
def main():
_, gateway_name, port = sys.argv
t = threading.Thread(target=lambda: start_http_server(int(port)), daemon=True)
t.start()
c = Counter('request_total', 'Response Status Counter', ['gw', 'cred_id'])
for line in sys.stdin:
m = re.search('"credid"\s*:\s*"([^"]*)"', line)
if not m:
continue
cred_id = m.groups()[0]
c.labels(gateway_name, cred_id).inc()
t.join()
if __name__ == "__main__":
main()
3.3 查询语句与 API 汇总
页面配置变量
这里使用网关(gw),活动ID(cred_id),错误码(errcode) 三个变量用于过滤曲线:
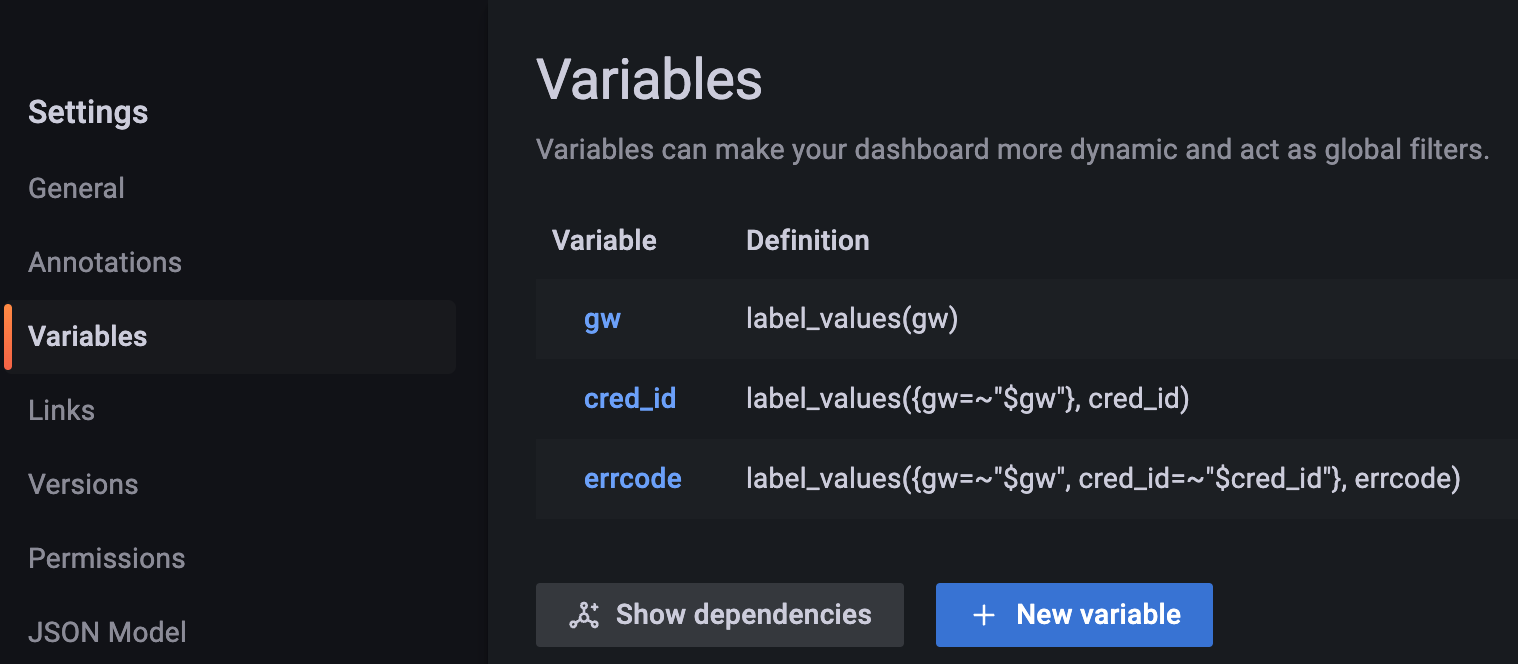
页面配置曲线
-- 按集群+CRED_ID+错误码曲线(服务实际返回状态码)
sum by(errcode, cred_id, gw) (rate(response_status_total{gw=~"$gw", cred_id=~"$cred_id", errcode=~"$errcode"}[$__rate_interval]))
-- 按集群+CRED_ID 访问曲线(入口流量)
sum by(cred_id, gw) (rate(request_total{gw=~"$gw", cred_id=~"$cred_id"}[$__rate_interval]))
-- 按集群的网关错误流量
sum by(cred_id, gw) (300*rate(response_status_total{gw=~"$gw",errcode="-10001"}[$__rate_interval]))
-- 按集群总入口流量
sum by(gw) (300*rate(request_total{gw=~"$gw"}[$__rate_interval]))
报表查询API
按照条件获取标签值的集合(Querying label values):
params = 'match[]={__name__="response_status_total", job="prometheus", gw="%s"}' % gw_
r = requests.get('http://localhost:9090/api/v1/label/cred_id/values', params=params)
output_cred_id = set((r.json()['data']))
普通查询,在某个时间点上 QL 对应的值(Instant queries);如果要查询一段时间,可以使用 GET /api/v1/query_range 接口,带上 start、end、step 等参数:
params = f'query={ql}&time={int(time.time())}'
r = requests.get("http://localhost:9090/api/v1/query", params=params)
result = r.json()['data']['result']
某个指标的在一段时间的增长值:
-- 一段时间内,某个指标的增长值
sum without (instance, errcode) (increase(response_status_total{job="prometheus", gw=~"$gw", cred_id=~"$cred_id"}[2h]))
报表内容
监控的目的是检查出哪些服务有异常,统计报表和曲线的侧重点不一样:
- 报表能够清晰地展示出异常的服务、具体是什么异常
- 曲线能够清晰地展示具体某个网关-活动的具体趋势变化
这里介绍在流量复制过程中对监控指标统计报表有哪些内容:
- 统计网关请求中有 而返回中没有的活动 ID
- 少量活动返回中没有 活动ID,只能通过上具体的服务观察日志和回包
- 少量活动中字段 int 填成 string,新网关按照固定协议解析失败,后做了兼容
- 统计网关错误1,过滤出前端有流量但是没有部署的服务
- 统计错误率,与线上活动的统计曲线/错误率进行比较
- 少量活动后台 Cache 数据异常,造成错误
- 少量活动请求量较低,健康检查返回错误码为1
- 域名/L5切换到新网关之后,对线上遗留活动的统计
- 极个别活动写死 L5/IP 配置,即使服务停止也不更新连接到新的 IP
- 内部少量适配服务,采用查询注册的方式获取网关地址
4. DRY
“Don’t repeat yourself” (DRY)
4.1 使用脚本生成脚本
上边提到的部署,涉及到多个老网关(每台网关需要部署一个 tcpcopy)、多个无侵入代理(每台代理上有一个Nginx、多个intercept、多个网络捕获监控)、多个新网关。如果手动去启动每个 tcpcopy/intercept、Nginx、网络捕获监控进程,会非常的复杂并难以维护。
这里在唯一一处维护着以下关系,使用 Python 脚本生成 Bash 脚本,保证每个网关上都使用完全相同的脚本&启动指令,每个代理上使用完全相同的脚本启动 intercept、捕获监控。
| 网关名称 | 老网关机器IP | 老网关端口 | 代理IP | 代理端口 | intercept端口 | 虚假Client IP段 | 监控端口 | 新网关CLB | 新网关端口 |
|---|---|---|---|---|---|---|---|---|---|
| ① | ② | ③ | ④ | ⑤ | ⑥ | ⑦ | ⑧⑨ | ⑩ | ⑪ |
每个网关上都使用完全相同的脚本&启动指令,脚本内部自动根据网关IP选择启动参数! (重复3遍)
以生成的代理上的脚本为例,先获得本机 IP,再利用 Bash 的 case 语法,匹配到对应的启动指令集。
function start_intercept {
in_name=`route -n |grep ^[0-9]|awk '{print $NF}'|sort|uniq -c|sort -n -k1 -r|head -1|awk '{print $NF}'`
ip=`/sbin/ifconfig ${in_name} |grep "inet"|grep -v inet6|awk '{print $2}'|sed 's#addr:##'|head -1`
ps -ef | grep "./intercept" | grep -v grep | awk '{print $2}' | xargs kill
case $ip in
10.10.224.174) # 根据代理IP过滤需要的启动指令
./intercept -i any -F 'tcp and (port 10010 or port 10011)' -p 28001 -d -l t1.log # serving gw(9.9.9.193)
./intercept -i any -F 'tcp and (port 10020 or port 10021)' -p 28002 -d -l t1.log # serving gw(9.9.9.194)
# ... 生成更多的intercept启动指令
;;
# ... 生成更多的case记录
esac
}
case $1 in
start_intercept|stop_intercept)
$1;
;;
*)
echo "invalid action"
;;
esac
对应之前提到进程的部署进程,都可以选择其中的几列信息,拼装生成脚本的脚本:
- tcpcopy: ②+③+④+⑤+⑥+⑦
- intercept: ④+⑤+⑥
- 监控入口流量: ①+④+⑤+⑧
- 监控新网关回包: ①+⑨+⑩+⑪
- Nginx 配置文件: ⑤+⑥+⑩+⑪
- Prometheus 配置文件: ⑤+⑧+⑨
4.2 Docker 镜像大小优化
迁移时,使用的基础镜像和运行镜像都是利用在运行的 Docker container 上运行 bash 构建出的镜像。这样产出的镜像比较大(7G),会影响构建和运行的效率,动辄 5 分钟以上。
这里利用 Docker 多层合并成一层的方法,将镜像大小减小到 2G。详细方式和原理点击 【后台技术】给Docker镜像瘦瘦身 查看。
4.3 其他脚本使用
部署新的无侵入机时,将Nginx 的安装、Docker 拉取和启动、文件夹的创建,都放到脚本中,避免重复工作。
迁移过程中,有使用到脚本做一些信息的快速采集:
- 从管理端抓取指定服务的启动目录/机器IP/数量
- 选择服务使用的一台 IP 抓取进程使用的内存/CPU、启动参数,用于评估迁移后使用的容器资源,以及填写运行镜像的启动指令
机器清理时使用脚本:
- Python + pyquery 批量抓取 TMP 上的机器CPU负载信息
- 蓝鲸作业平台+脚本抓取待清理机器上的内存和CPU TOP 10进程
- 使用 os_is_clear.pl 脚本检查脏进程/数据
4.4 导出/导入 Grafana 配置
容器有重启的风险,因此需要及时地将配置好曲线进行导出,当容器重启时能一键导入便可以恢复。
- 选择 Export for sharing externally 然后保存 JSON 文件
- 导入时,则需要在侧边栏寻找
5. 扩展讨论
TODO:如果请求中包含修改请求,该如何做流量复制?